
MySQL数据库教程(四)
表的创建(增)
建表属于DDL语句,DDL包括:create drop alter1
create table 表名(字段名1 数据类型,字段2 数据类型);
表名:建议以t或者tb开始,可读性强
关于MySQL中的数据类型
常见的数据类型:
varchar
可变长度的字符串,节省空间,但是效率低
会根据实际的数据动态的分配空间
char
定长字符串,使用不当可能会导致空间的浪费,效率高
不管实际数据长度多少,分配固定长度的空间去存储数据
int
数字中的整型
bigint
数字中的长整型
float
单精度浮点型数据
double
双精度浮点型数据
date
短日期类型
datetime
长日期类型
clob
字符大对象
最多可以存储4G的字符串
例如:存储一篇文章
blob
二进制大对象
专门用来存储图片、声音、视频等流媒体数据。
案例: 写一个电影表t_move(专门存储电影信息的)1
2
3
4编号名字 描述信息上映日期时长 海报 类型
no(bight)name(varchar)desoription(clob)playtime(date)time(double) image(blob) type(char)
10000 哪吒 ......... 2019-10-11 2.5 ...... '1'
10000 林正英之娘娘 ......... 2019-11-11 1.5 ...... '2'
删除表(删除整个表)
1 | drop table 表名;(当这张表不存在的时候会报错) |
1 | drop table if exists 表名;(如果这张表存在的话,删除) |
插入数据(insert)
语法格式
1 | insert into 表名(字段名1,字段名2,字段名3....) |
注意:
1.字段名和值要一一对应,数量要对应,数据类型要对应。
2.insert语句但凡是执行成功了,那么必然会多一条记录
3.没有给别的字段指定值的话,默认值是NULL
insert插入多条语句1
insert into 表名(字段名1,字段名2,字段名3....) values(值1,值2,值3...),(值1,值2,值3...),(值1,值2,值3...);
将查询结果插入一张表中1
insert into 新建的表名 select 字段名 from 表名;
insert插入日期
str_to_date
将字符串varchar类型转换成date类型1
str_to_date('字符串日期','日期格式')
日期格式:
%Y年
%m月
%d日
%h时
%i分
%s秒
注意:MySQL默认的日期格式是:%Y-%m-%d
date_format
将date类型转换成具有一定格式的varchar字符串类型,展示设置的日期格式1
date_format(日期类型数据,'日期格式')
date和datetime的区别
date:是短日期,只包括年月日信息
datetime:是长日期,包括年月日时分秒信息
MySQL短日期默认格式:%Y-%m-%d
MySQL长日期默认格式:%Y-%m-%d %h:%i:%s
在MySQL中获取系统当前时间
now() 函数,并且获取的时间是datetime类型的
auto_increment
数据自增,类似于数据++1
定义字段名 auto_increment
注意:只能用于主键值自增
表的数据修改(改)
修改表:update
语法格式:1
update 表名 set 字段名1=值1,字段名2=值2,字段名3=值3.... where 条件;
注意:没有条件整个表的数据都会被修改
表的数据删除
删除数据:delete
语法格式:1
delete from 表名 where 条件;
注意:没有条件整个表的数据都会被删除
快速创建表
1 | create table 创建的表名 as select 字段名 from 表名;(把查询结果当做一张表新建) |
快速删除表中的数据
delete删除效率比较低,支持恢复
truncate删除效率高,物理删除,不支持恢复1
truncate table 表名;
表结构的增删改
对表结构的修改需要使用:alter
添加一个字段
如:需求发生改变,需要向 t_student 中加入联系电话字段,字段名称为:contatct_tel 类型为 varchar(40)1
alter table t_student add contact_tel varchar(40);
删除一个字段
如:删除联系电话字段1
alter table t_student drop contact_tel;
更改一个字段
如:student_name 无法满足需求,长度需要更改为 1001
alter table t_student modify student_name varchar(100);
更改一个字段名
如:sex 字段名称感觉不好,想用 gender 那么就需要更爱列的名称1
alter table t_student change sex gender char(2) not null;
约束(constraint)
在创建表的时候,我们可以给表中的字段加上一些约束,来保证这个表中数据的完整性、有效性
约束的作用就是为了保证表中的数据有效
约束的包括
非空约束:not null
唯一性约束:unique
主键约束:primary key(简称PK)
外键约束:foreign key(简称FK)
检查约束:check(MySQL不支持,cracle支持)
非空约束
not null,表示必须在这个字段不能为空1
2
3
4create table 表名(
定义字段名 not null,
定义字段名 not null
);
唯一性约束
unique,表示不能重复,但是可以为null
列级约束
1 | create table 表名( |
表级约束
两个字段联合起来具有唯一性1
2
3
4
5create table 表名(
定义字段名1,
定义字段名2,
unique(字段名1,字段名2)
);
主键约束
primary key(简称PK)
主键约束的相关术语
主键约束:就是一种约束
主键字段:该字段上添加了主键约束,这样的字段叫做主键字段
主键值:主键字段中的每一个值都叫做主键值
主键的作用
主键值是每一行记录的唯一标识,类似身份证号
注意:任何一张表都需要主键,没有主键,表无效
主键的特征
not null + unique(主键值不能为null,也不能重复,换句话说,身份证号不能为空,也不能重复)
列级约束
1 | create table 表名( |
注意:主键约束只能添加一个
表级约束
复合主键1
2
3
4
5create table 表名(
定义字段名1,
定义字段名2,
primary key(字段名1,字段名2)
);
单一主键1
2
3
4
5create table 表名(
定义字段名1,
定义字段名2,
primary key(字段名1)
);
自然主键:主键值是一个自然数,和业务没关系
业务主键:主键值和业务紧密关联
unique和not null的联合
1 | create table 表名( |
外键约束
foreign key(简称FK)
外键约束的相关术语
外键约束:一种约束
外键字段:该字段上添加了外键约束
外键值:外键字段当中的每一个值
外键约束的作用
假设表1和表2存在某种关系,当表2用到表1的某种字段,如果表2用到的字段中的数据,表1不存在,这个时候就需要给该字段添加外键约束,那么,该字段就是外键字段,该字段中的每一个值都是外键值
注意:
表1是父表
表2是子表
删除表的顺序
先删子再删父
创建表的顺序
先创建父在创建子
删除数据的顺序
先删子再删父
插入数据的顺序
先插入父再插入子1
2
3
4
5
6
7
8
9create table 父表(
定义字段名1,
定义字段名2,
);
create table 子表(
定义字段名3,
定义字段名4,
foreign key(字段3) references 父表(字段1)
);
注意:
1.外键值可以为null
2.子表中的外键引用的父表中的某个字段,被引用的这个字段不一定是主键,但前提是必须具有唯一性(unique)
删除约束
删除外键约束1
alter table 表名 drop foreign key 外键(区分大小写);
删除主键约束1
alter table 表名 drop primary key;
删除约束1
alter table 表名 drop key 约束名称;
添加约束
添加外键约束1
alter table 子表 add constraint 约束名称 foreign key 子表(外键字段) references 父表(外键字段);
添加主键约束1
alter table 表 add constraint 约束名称 primary key 表(主键字段);
添加唯一性约束1
alter table 表 add constraint 约束名称 unique 表(字段);
存储引擎
存储引擎:MySQL中特有的术语,是表存储或者组织数据的方式,不同的存储引擎,表存储的数据方式不同
查看存储引擎
1 | show create table 表名 |
更改存储引擎
在建表的时候可以在最后小括号的右边使用
engine来指定存储引擎
charset来指定这张表的字符编码方式1
2
3
4create table 表(
定义字段名1,
定义字段名2,
)engine=InnoDB default charset=utf8;
注意:
MySQL默认的存储引擎是:InnoDB
MySQL默认的字符编码方式是:utf8
查看当前MySQL支持哪些存储引擎
1 | show engine \G |
常用的存储引擎
MyISAM存储引擎
特征:
使用三个文件表示每个表
格式文件—存储表结构的定义
数据文件—存储表行的内容
索引文件—存储表上的索引
可被转换为压缩、只读表来节省空间
不支持事务机制,安全性低
InnoDB存储引擎
这是MySQL默认的存储引擎
InnoDB支持事务,支持数据库崩溃后自动恢复机制。
InnoDB存储引擎最主要的特点是:非常安全。
它管理的表具有下列主要特征:
– 每个 InnoDB 表在数据库目录中以.frm 格式文件表示
– InnoDB 表空间 tablespace 被用于存储表的内容(表空间是一个逻辑名称。表空间存储数据+索引。)
– 提供一组用来记录事务性活动的日志文件
– 用 COMMIT(提交)、SAVEPOINT 及ROLLBACK(回滚)支持事务处理
– 提供全 ACID 兼容
– 在 MySQL 服务器崩溃后提供自动恢复
– 多版本(MVCC)和行级锁定
– 支持外键及引用的完整性,包括级联删除和更新
InnoDB最大的特点就是支持事务:
以保证数据的安全。效率不是很高,并且也不能压缩,不能转换为只读,
不能很好的节省存储空间。
MEMORY存储引擎
该存储引擎数据存储在内存中,且行的长度固定,这两个特点使得该引擎非常快
MEMORY 存储引擎管理的表具有下列特征:
– 在数据库目录内,每个表均以.frm 格式的文件表示。
– 表数据及索引被存储在内存中。(目的就是快,查询快!)
– 表级锁机制。
– 不能包含 TEXT 或 BLOB 字段。
MEMORY 存储引擎以前被称为HEAP 引擎。
MEMORY引擎优点:查询效率是最高的。不需要和硬盘交互。
MEMORY引擎缺点:不安全,关机之后数据消失。因为数据和索引都是在内存当中。
事务(transaction)
事务概述
一个事务就是一个完整的业务逻辑
一个事务其实就是多条增删改语句同时成功或者同时失败
注意:只有增删改和事务有关系,其它都没有关系
实现事务
在事务的执行过程中,每一条DML的操作都会记录到“事务性活动的日志文件”中,在事务的执行过程中,我们可以提交事务,也可以回滚事务
提交事务
清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中
提交事务标志着,事务的结束,并且是一种全部成功的结束1
commit;
回滚事务
将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件
回滚事务标志着,事务的结束,并且是一种全部失败的结束1
rollback;
注意:在MySQL默认情况下是支持自动事务提交的,即每执行一条DML语句,则提交一次
关闭MySQL自动提交命令
1 | start transaction; |
事务特性
A:原子性
说明事务是最小的工作单元,不可再分
C:一致性
所有事务要求,在同一个事务当中,所有操作必须同时成功或者同时失败,以保证数据的一致性
I:隔离性
A事务和B事务之间具有一定的隔离
D:持久性
事务最终结束的一个保障,事务提交,就相当于将没有保存到硬盘上的数据保存到硬盘上
事务的隔离性
查看隔离级别
1 | select @@tx_isolation; |
隔离级别
读未提交:read uncommitted(最低的隔离级别)
事务A可以读取到事务B未提交的数据
存在的问题是:脏读现象,称作脏数据1
set global transaction isolation level read uncommitted;
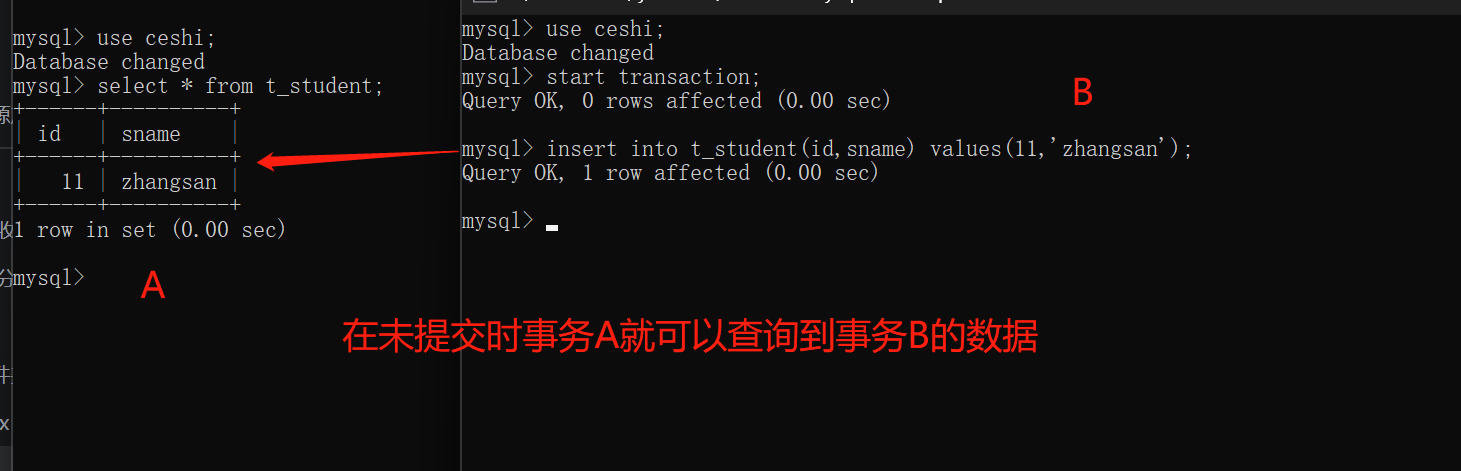
注意:这种隔离级别一般都是理论上的,大多数的数据库隔离级别都是二档起步
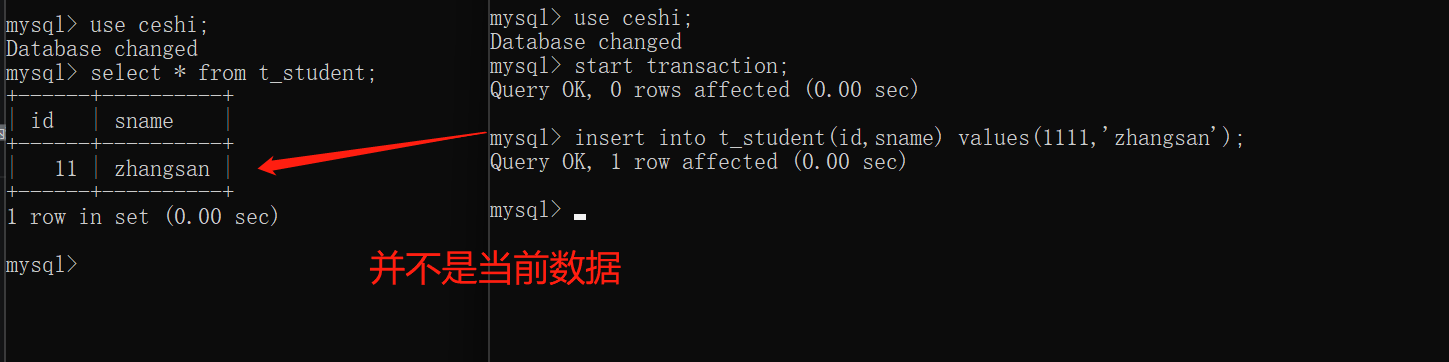
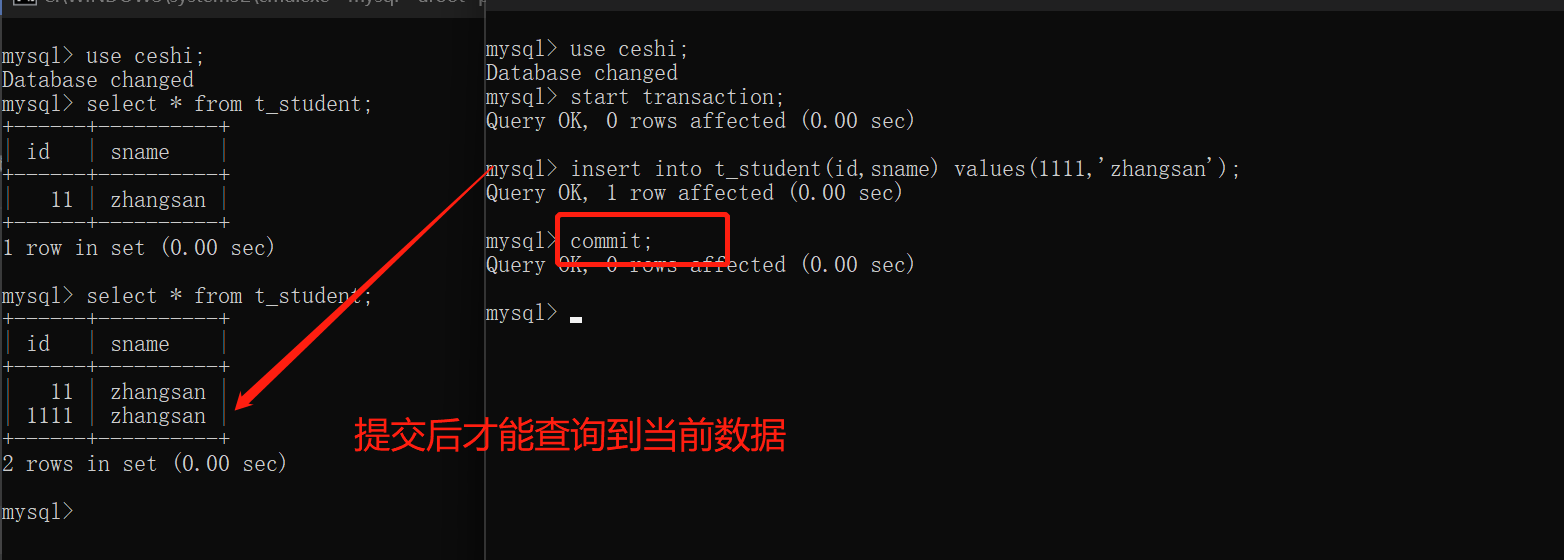
读已提交:read committed
事务A只能读取到事务B提交之后的数据
解决了脏读的现象
存在的问题:不可重复读取数据1
set global transaction isolation level read committed;
可重复读:repeatable read
事务A开启之后,不管是多久,每一次在事务A中读取到的数据都是一致的,即使事务B将数据已经修改,并且提交了,事务A读取到的数据还是没有发生改变,这就是可重复读
解决了不可重复读取数据
存在的问题:会出现幻影读
每次读取的数据丢失幻想,不真实1
set global transaction isolation level repeatable read;
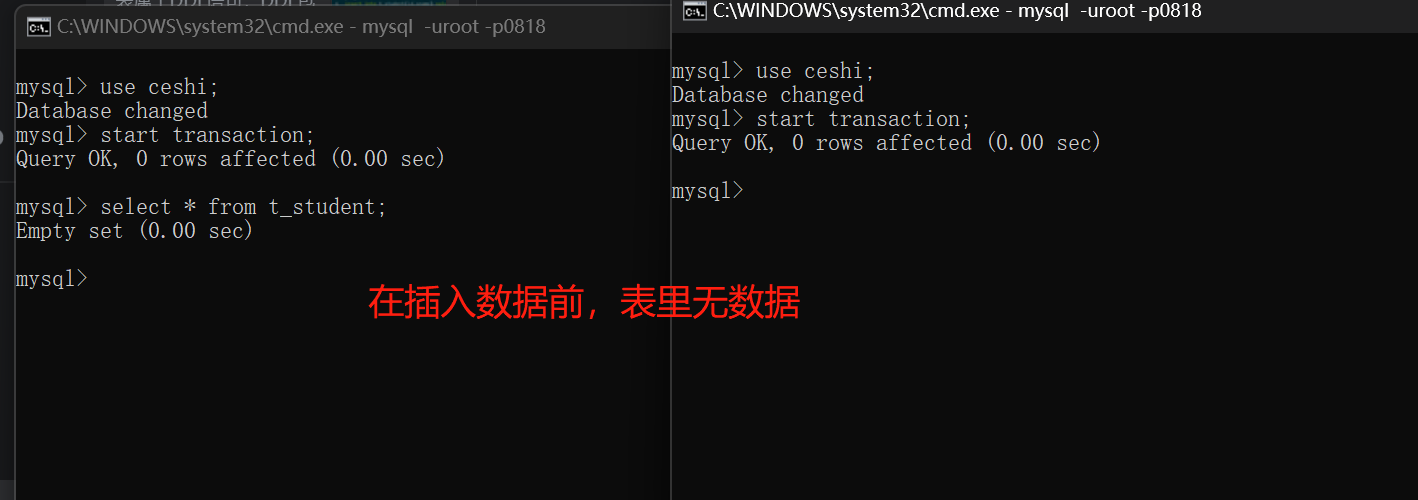
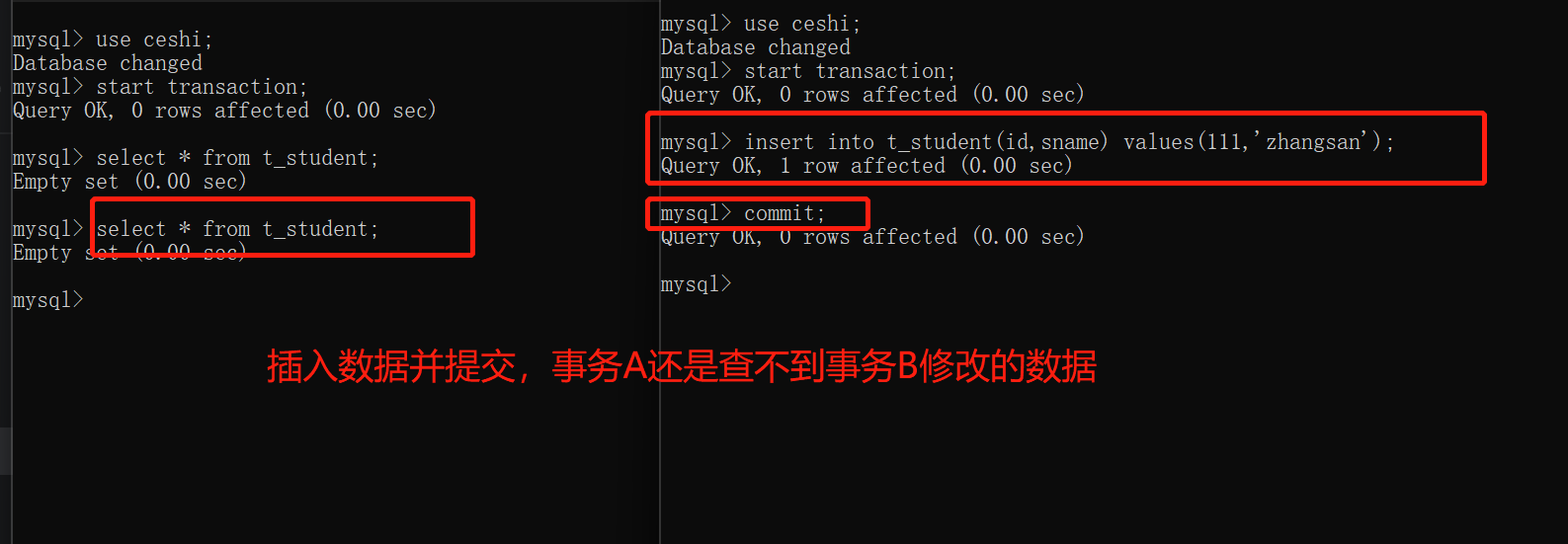
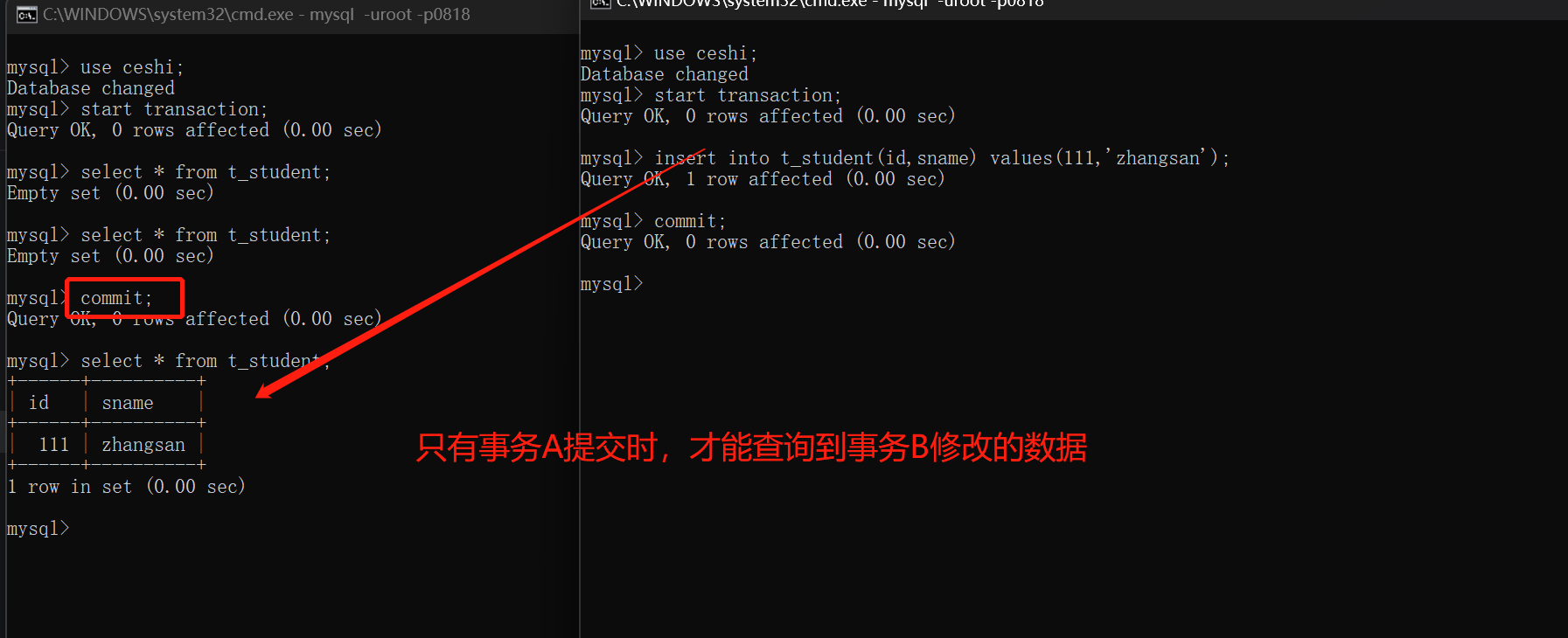
注意:MySQL默认的就是这种隔离级别
序列化/串行化:serializable(最高的隔离级别)
每一次读取的数据都是真实的,解决了所有的问题,并且效率最低1
set global transaction isolation level serializable;


索引
索引概述
索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。
一张表的一个字段可以添加一个索引,当然多个字段联合起来也可以添加索引。
索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
索引的实现原理
1.在任何数据库当中主键上都会自动添加索引对象,另外,如果一个字段上有unique约束的话,也会自动创建索引对象。
2.在任何数据库中,任何一张表的任何一条记录在硬盘存储上都有一个硬盘的物理存储编号。
3.在mysql中,索引是一个单独的对象,不同的存储引擎以不同的形式存在。索引都会以树的形式存在。遵循左小右大原则。
4.在什么条件下需要添加索引
数据量庞大。
某个字段经常出现在where的后面,以条件的形式存在。
某个字段很少的DML操作(增删改)。
索引的创建
1 | create index 索引名 on 表(字段); |
索引的删除
1 | drop index 索引名 on 表; |
查看是否使用了索引
1 | explain select * from 表 where 条件; |
索引失效
1.模糊查询时,以%开始,就会出现索引失效
2.使用or时会失效,如果使用or那么要求or两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个字段上的索引也会实现。
3.使用复合索引的时候,没有使用左侧的列查找,索引失效
两个字段或者更多字段联合起来添加一个索引,叫做复合索引
4.在where当中索引列参加了运算,索引失效。
5.在where当中索引列使用了函数。
视图(view)
视图的概述
view:站在不同的角度看待同一份数据
创建视图对象
1 | create view 视图名 as select 字段 from 表; |
删除视图对象
1 | drop view 视图名; |
视图的作用
可以面向视图对象进行增删改查,对视图对象的增删改查,会导致原表被操作。
DBA命令
数据导出
导出数据库
1 | mysqldump 数据库名 > 路径 -uroot -p |
导出数据库中的表
1 | mysqldump 数据库名 表 > 路径 -uroot -p |
注意:在Windows的dos命令窗口中使用
数据的导入
1 | source 路径 |
数据库设计三范式
数据库表的设计依据
第一范式
要求任何一张表必须有主键,每一个字段原子性不可再分
第二范式
是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖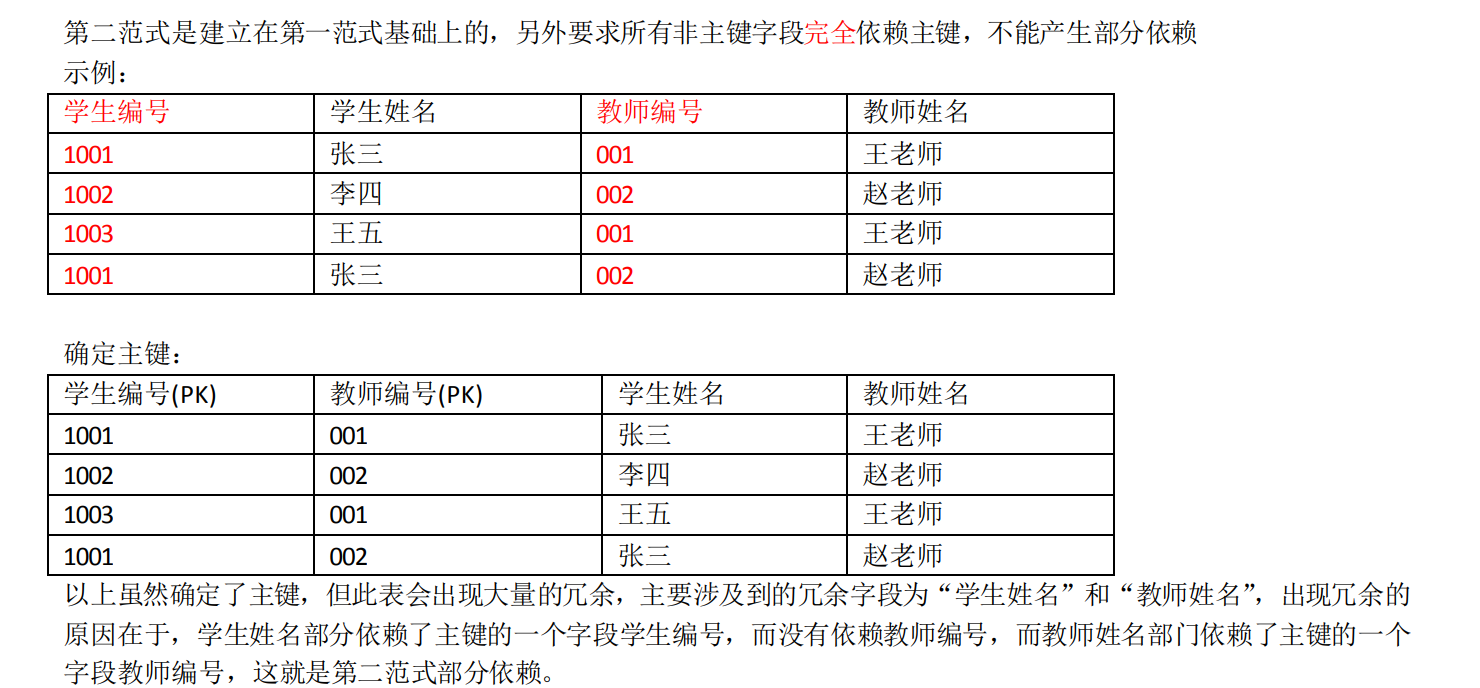

背口诀:
多对多,三张表,关系表两个外键
第三范式
建立在第二范式基础上的,非主键字段不能传递依赖于主键字段。(不要产生传递依赖)
背口诀:
一对多,两张表,多的表加外键
口诀:一对一,外键唯一




